皮皮蝦
Will update later on.



正文
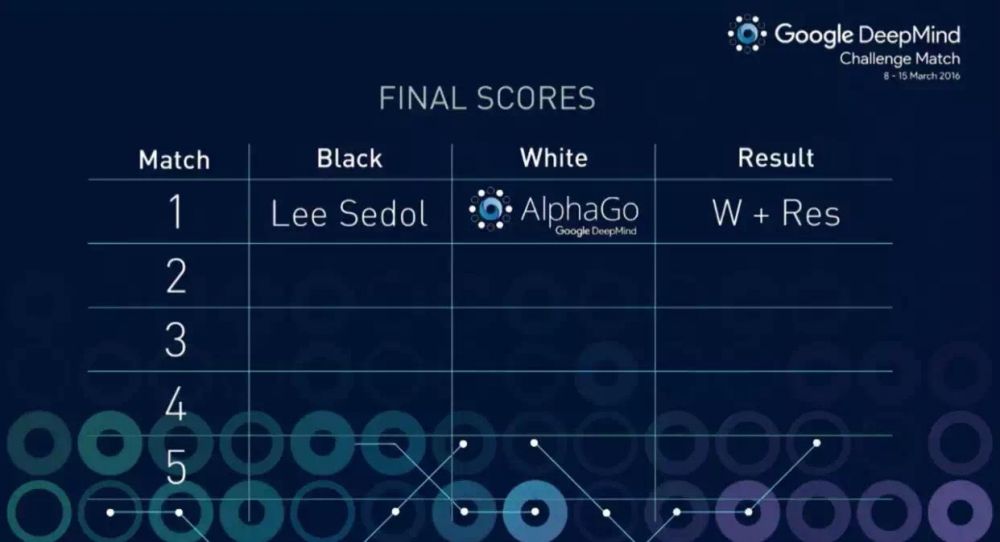
你一定猜出来了,我所说的人类的伟大失败是指昨天谷歌开发的阿尔

或曰:这只是第一盘,还有四盘呢?虾答:对!

现在傻眼了吧?昨天这盘棋之前,
又或曰:李世石不是人类的最佳代表。最近风头最劲、

拿世界冠军最多、开创一个时代的李昌镐(个人18冠、
有人把李昌镐与吴清源相提并论,其实吴可能是个更厉害的角色,
不过吴清源的关门弟子、女中豪杰芮乃伟倒不失为一个可能的人选,
当年女中豪杰芮乃伟在李昌镐最牛且打败天下无敌手的时候,

对不起,此图黑白颠倒就好了!
吴清源在日本为中国人争了气,那时中国围棋全面落后于日本。
又又或曰:为什么欢呼人类失败?虾应:

知道你会问这次这个电脑怎么这么牛。
按理对于围棋这种目前世界上难度最大的智力游戏,
可是谷歌就迎难而上敢于挑战难度。其实这之前,脸书也做了尝试,
据说谷歌的DeepMind项目小组在设计AlphaGo的深度
记得十多年前本虾与一位留美的前北大美学教授谈起武宫正树的宇宙
这一次革命不同于老校长所说的文化革命,是真正颠覆性的。
管它呢,先欢呼了再说。
****** 编后语 *******
欢迎转发,欢迎提问或评论。请关注公众号。
打开手机微信,点击右上角加号,选择“扫一扫”(Scan QR Code),扫描图中二维码,选择进入(Enter official account)即可。


评论
目前还没有任何评论
登录后才可评论.