泥土的气息
泥土也有生命气息



Source: https://atscaleconference.com/calling-relay-infrastructure-at-whatsapp-scale/?
WhatsApp 历史和规模
自2015年推出 WhatsApp 的通话功能以来,它的通话中继基础架构一直负责在用户之间高可靠、低延迟地传输语音和视频数据。从一对一语音通话开始,接着是视频通话,再到群组通话,WhatsApp 的使用量随着时间呈指数级增长。该应用现在已成为世界上最大的通话产品之一,每天传输超过10亿次通话。由于规模如此惊人,我们遇到了很少有通话产品会遇到的独特问题。我们不断发展中继架构,以跟上不断增长的规模和容量需求。
WhatsApp 原则
WhatsApp 建立在隐私、简单和可靠性这些核心原则之上。
为确保不可被破坏的隐私,WhatsApp 早期就决定对所有通信(包括语音和视频通话)强制执行端到端加密。这意味着中继服务器无法访问流经其中的媒体内容,因此中继无法对媒体进行升级/降级、转码或任何其他修改。
为确保简单性,我们专注于通过聚焦并完善最重要的功能为用户提供无干扰体验。从用户界面到服务器架构,一切都遵循这一原则。我们自定义的 WASP(WhatsApp STUN 协议)就是一个例子。用户设备与中继服务器通信的标准协议是 TURN。TURN 是一种相当复杂的协议,使用多个临时端口、无法很好地与防火墙配合使用,并且在分布式架构中无法很好地扩展。WASP 的核心与 TURN 相似,但 WASP 仅使用一个端口进行所有网络通信,并更多地依赖用户设备来做出决策和跟踪连接状态,这对于中继服务器故障转移来说效果很好。
为确保可靠性,我们的目标一直是确保任何人都可以拨打 WhatsApp 通话——无论是在高速网络上使用最新设备,还是在网络状况不佳时使用低端设备。我们希望通话功能可以可靠运行,即使在极端负载时,因为那可能是人们最需要与亲朋好友联系的时候。
什么是通话中继?
两个关键的基础设施可以让 WhatsApp 用户进行通话:信令服务和通话中继服务。
信令服务器协助设置通话的初始过程。当有人拨入时,它负责让设备响铃;当用户接听时,它负责连接通话。
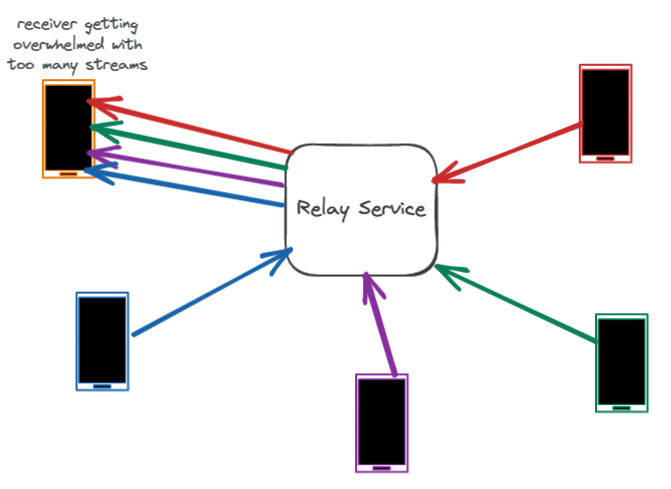
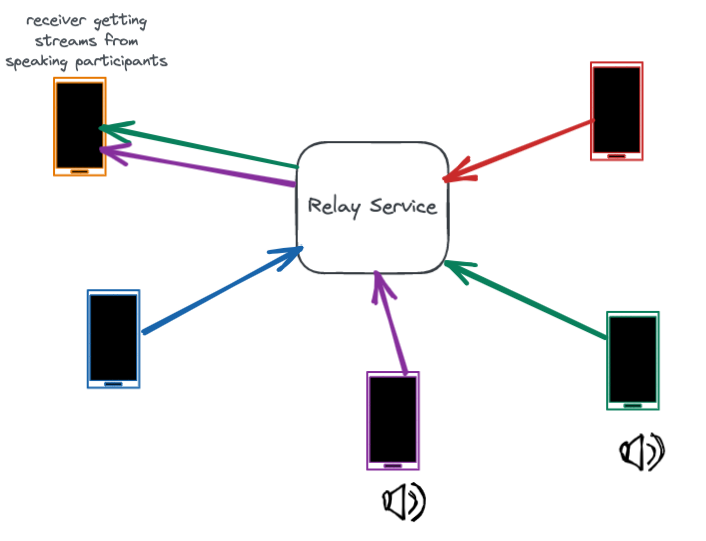
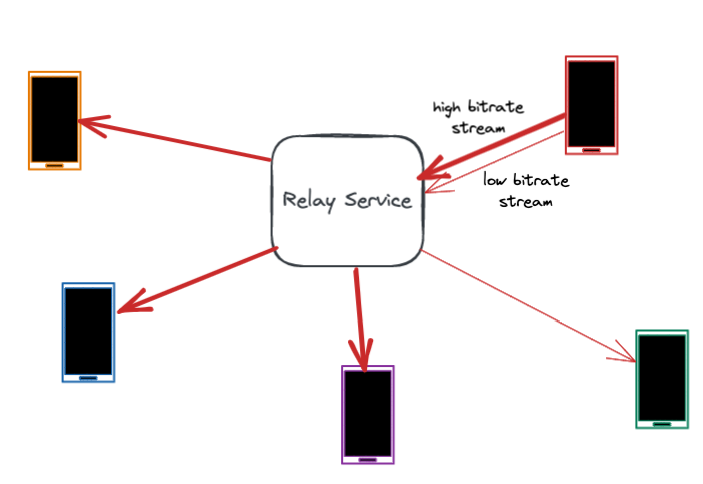
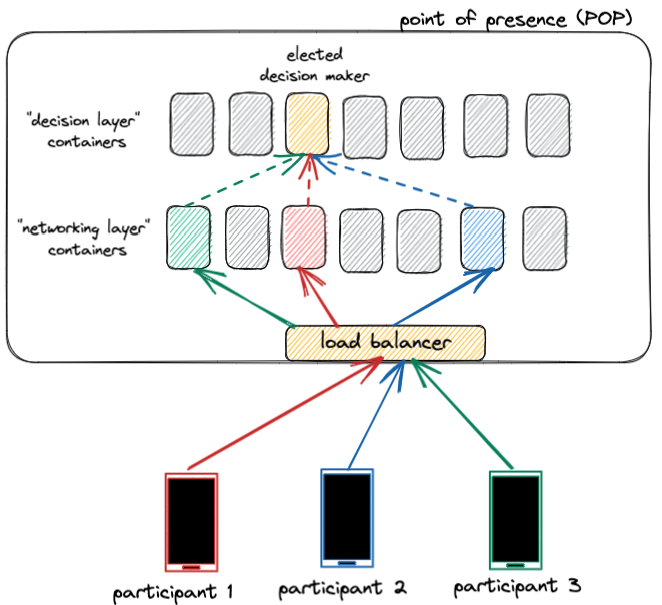
一旦通话建立,中继服务在整个通话期间起到维护连接的重要作用。通话中继在用户设备之间来回传输音频和视频数据包。
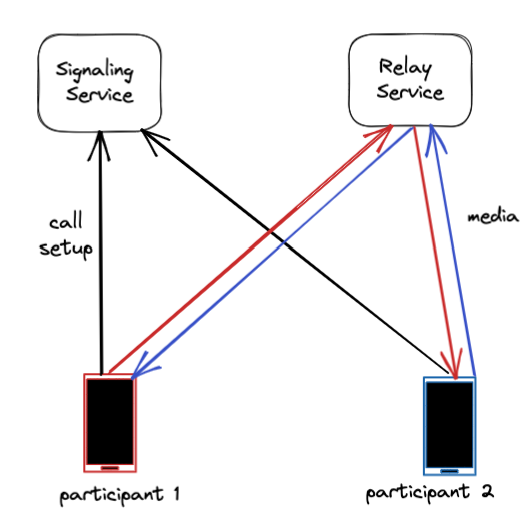
通话中继解决了与建立 WhatsApp 通话相关的一些关键技术挑战。
改善网络延迟和数据包损失问题
最好的通话应当像亲自交谈一样对话自然流畅,没有延迟或中断。这是我们为每次通话所追求的终极目标。两个关键的技术挑战会影响通话的临场感:网络延迟和数据包损失。
网络延迟会导致对话滞后,干扰对话的自然流畅度。延迟还会大大降低通话算法的最优运行,因为它们最终会在过时的信息上运行。
数据包损失会导致视频冻结、音频机器人化等问题,严重影响通话体验。
延迟
改善延迟的最佳方式是通过尽可能最短的路径路由通话——这意味着将中继服务托管在离终端用户尽可能近的位置。
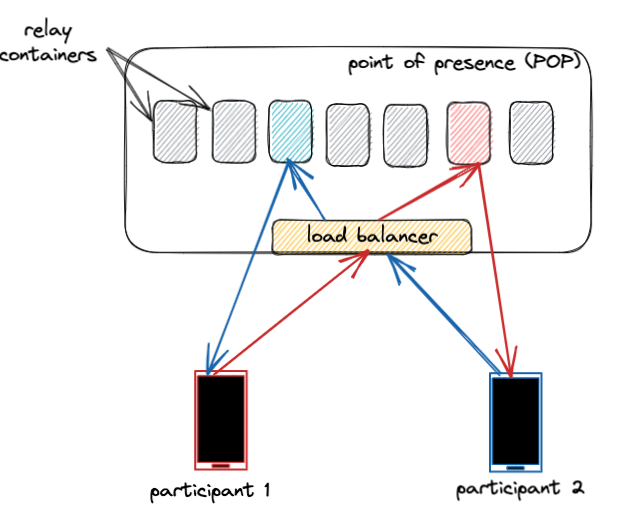
为此,我们设计了WhatsApp中继基础设施,使其可在Meta在全球各地建立的数千个接入点(PoP)上运行。这些PoP最初是为了服务于Meta的内容交付网络(CDN),能够满足Facebook和Instagram等产品对其提出的大规模需求。
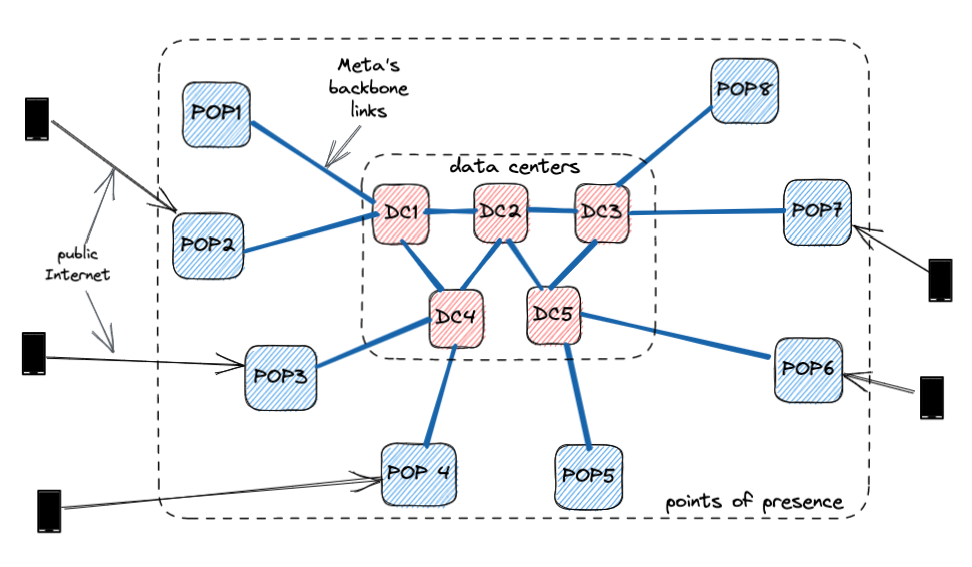
由于这些接入点分布在比数据中心更多的区域,中继服务距离终端用户更近,从而降低了WhatsApp通话的延迟。另外,这些接入点集群通过极高质量和专用主干链路互联。
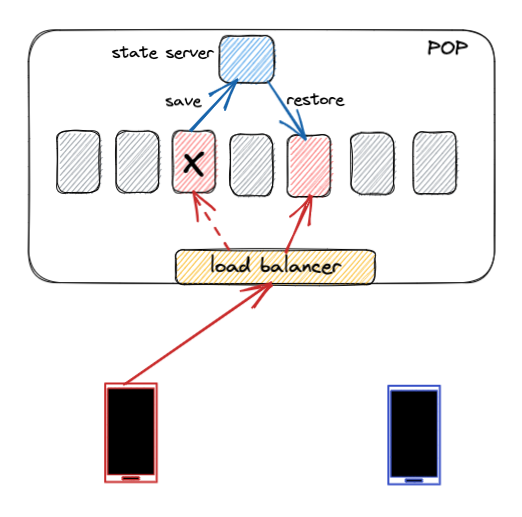
仅靠近终端用户是不够的;我们还必须为每次WhatsApp通话选择最佳集群。为此,我们对历史延迟数据应用复杂的定位算法,计算出每次通话的最佳集群。通话过程中,最优集群可能会发生变化——例如,当用户从WiFi切换到蜂窝网络时。如果我们检测到正在进行的通话条件发生显著变化,我们会重新计算最优集群。
数据包损失
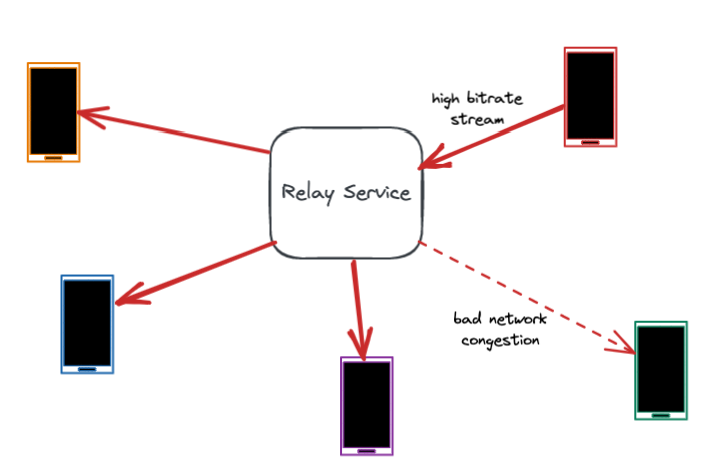
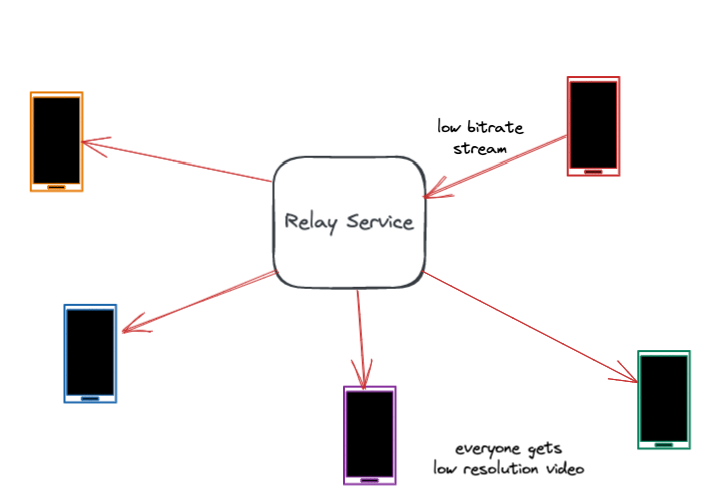
解决数据包损失的最佳方式是防患于未然。大多数数据包损失源于网络拥塞,而拥塞是由于带宽使用不当(发送太多数据)造成的,通常是由于不准确地估计网络链路带宽所致。因此,准确估计带宽和调节比特率是防止拥塞的关键。
然而,带宽是高度可变的,在通话过程中会发生波动。许多数据包丢失和带宽问题发生在最后一公里,比如用户的WiFi网络中。中继服务器协助准确估计每一段通话的带宽。它通过测量数据包延迟和数据包丢失,并将这些作为反馈共享给用户设备。快速准确地估计带宽有助于设备调整比特率,减少网络拥塞和数据包丢失。
某些网络无论是否拥塞都会导致数据包丢失。在这种丢包网络中,中继服务使用主动数据包丢失缓解技术。其中一种技术称为NACK(否定确认)。中继服务器会缓存几秒钟的媒体数据包,并响应设备发送的NACK重传这些数据包。与端到端重传相比,从中继服务重传效率更高,因为中继位于通话参与者之间的中间位置,减少了重传的延迟。另外,中继更有效率,因为它能够只在丢包的链路上重传数据包。