阶梯上的思索
为何我写作?------我心中所蕴蓄的必得流露出来,所以我才写作。




五、伪民主制度与神经网络
让我们先把围棋的话题岔开,绕到两个风马牛不相及的问题上。不过这里讨论的可不是什么政治制度问题,而是想以一种假想的代议投票机制为例把神经网络的基本原理说清楚。
神经网络,这个当今人工智能领域里炙手可热的名词,既充满神秘感又给人以无穷的想象。人工智能专家宣称,神经网络是模仿人类智慧大脑中的生物学网络搭建而成,可以通过接受训练而产生新功能,具有自我学习、纠错和进化的能力。这类描述带给人的感觉是神经网络可以像小孩子一样学习新鲜事物,从不懂到懂,从懂到专业,从专业到更专业,直至最终超越人类。
大量基于神经网络技术的产品的问世也似乎在证明这一点:谷歌的物体识别技术已经能够轻松地识别出混杂在同一张照片中的不同物体;各种能听懂人类语言的电子产品正在悄然进入我们的日常生活之中;最新的智能游戏机能够看懂人的不同姿势和动作……
很多初次接触神经网络的人都会觉得这实在是一门让人神经错乱的学科:介绍这种技术的书籍往往首先会将神经网络与人脑的神经系统相比较,指出其相似性,然后就突然祭出一大堆专有名词和数学公式,似有不把读者推入五里雾中誓不罢休之感。
然而,即使是那些经过多年苦行,对神经网络早已大彻大悟的学者们在向新人介绍这一概念时,似乎也会忘记当年自己的神经是如何被它苦不堪言地折磨,照例搬出大量专有名词及晦涩的数学公式为其罩上一层又一层的面纱。
究其原因,恐怕就是因为神经网络的学习过程完全是“暗箱操作”。人工智能专家可以训练一个网络做各种各样神奇的事情,然而如果要问在这个学习过程中,网络中哪个参数的变化直接导致了输出结果的更优化,恐怕没有人能说得清。正因为如此,人们对神经网络的认识,只能停留在非常肤浅的与人类大脑结构的物理相似性之上。
其实,隐藏在神经网络背后的基本思路非常简单,因为其运行机理,很容易用当代人非常熟悉的代议制民主制度来解释清楚。
让我们来假想一种代议制民主制度。在这种制度中,选民手中的选票并不能直接决定一个议案的通过与否。但这些选票能影响议员投赞成票或反对票而最终导致议案的成败。
让我们把问题做一次简化,假定直接投票的选民总共有五人:一个白人、一个印第安人,此外,亚裔、非裔、拉美裔各一名。这些人的政治理念不同,对于每个议案的投票也会有自己的选择。
假定议员共有三人,分别是A、B和C。每个议员可以声称自己会代表一个或多个选民的利益。例如,议员A声称自己代表白人和亚裔的利益,而议员B则声称自己代表非裔和拉美裔的利益。
投票的过程是这样的:选民投票之后,议员必须根据选民的投票结果决定自己是投赞成票还是反对票。不过,议员在做出自己的决定时,只会考虑自己所代表选民的投票情况:只有在赞成票数达到或超过半数以上时,该议员才会投赞成票,反之则必须投反对票。
例如,议员A声称自己代表白人和亚裔的利益,在投票时他不会去看印第安人、非裔和拉美裔的投票结果。只要白人或亚裔有一人投赞成票,议员A就会投赞成票;只有在白人和亚裔都投反对票的时候,议员A才会投反对票。
议员这一级的投票结果最终决定法案是否通过。要想通过一条议案,议员的投票数必须过半,也就是说,至少要有两票。
这样一个机制看上去非常公平。但现在让我们假定政治家们都是些口是心非之徒,他们打算利用这个系统操控民意。接下来将要投票表决的有三个法案:平权法案,减税法案和禁枪法案。政治家们出于自身利益的考虑,都希望通过前两条法案而否决第三条法案。
由于这些法案的敏感性,政治家们已经可以准确地预测各个选民在投票时的表现。下表格就是他们的预测(1代表投赞成票,0代表投反对票):
|
| 白人 | 印第安人 | 亚裔 | 非裔 | 拉美裔 |
| 平权法案 | 1 | 0 | 0 | 1 | 0 |
| 减税法案 | 1 | 1 | 1 | 0 | 0 |
| 禁枪法案 | 0 | 1 | 1 | 0 | 1 |
如果看选民的绝对票数,我们知道最后被通过的应该是减税(3票)和禁枪法案(3票),而平权法案(2票)通不过。不过由于实行的是代议制,政治家们便有了可乘之机。他们只是略施了些手腕,就让最后的投票结果倒了过来:平权及减税法案被通过,而禁枪法案被否决。
议员的投票应该综合所代表选民的投票结果,他们不能自作主张地投与选民投票结果相悖的票。既然如此,他们是怎样做到改变投票结果的呢?很简单,三个议员看到白人和非裔的政治制度与自己的利益相同,于是都声称自己将代表这两个选民的利益。这样,他们就都可以为平权法案投赞成票而为禁枪法案投否决票了。
但如果忽视其他族裔的利益,减税法案就通不过。于是三名议员又分别各增加了一个所代表的选民(只能增加一个,再多禁枪法案就会被通过):
A说,除了白人和非裔,我还代表印第安人。根据我所代表的选民的投票结果,我被授权对平权法案和减税法案投赞成票。
B说,除了白人和非裔,我还代表亚裔。根据我所代表的选民的投票结果,我被授权对平权法案和减税法案投赞成票。
C说,除了白人和非裔,我还代表拉美裔。根据我所代表的选民的投票结果,我被授权对平权法案投赞成票。
最终投票结果:平权法案三票通过,减税法案两票通过,禁枪法案零票被否决。
虽然政治制度不是这么玩的,然而神经网络就是这么玩的。整个投票的机制可以用下面这个图来表示:
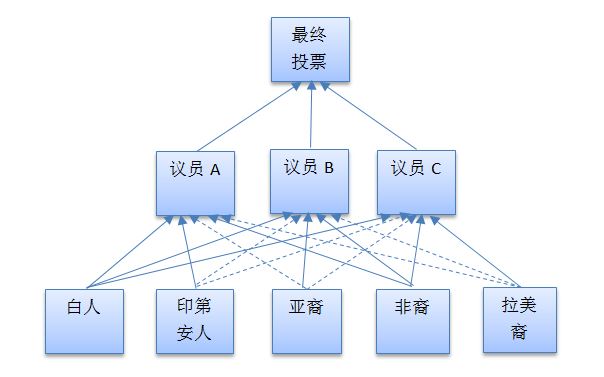
在这个两级投票系统中,个体的投票不能直接决定议案的通过与否,却可以左右代表他们的议员的投票。图中,每个个体的投票被送往所有的议员,只是有的议员代表他们的利益(用实线表示),有的议员不代表他们的利益(用虚线表示)。
在上图中,只有通过实线送至议员的投票才有效。举例来说,指向议员C的有三根实线,分别来自白人,非裔和拉美裔。因此只有这三个人的投票才会对C的投票产生影响。
我们也可以换一种方式来表述这个问题:让个体选民的投票对每位议员都有效,只不过给他们的投票加上权重。
怎样加权重呢?很简单:假如你是我所代表的族裔,你对我影响的权重就是1,假如你不是我所代表的族裔,你对我影响的权重就是0。也就是说,上图中实线的权重都是1,而虚线的权重都是0。
下表便是本例中议员A、B、C对选民所加的不同权重:
|
| 白人 | 印第安人 | 亚裔 | 非裔 | 拉美裔 |
| 议员A | 1 | 1 | 0 | 1 | 0 |
| 议员B | 1 | 0 | 1 | 1 | 0 |
| 议员C | 1 | 0 | 0 | 1 | 1 |
权重是1的,你投一票我这儿就给你数一票。权重是0的,你投不投票我这儿都数0票。
再做一个换汤不换药的修正:议员只有在自己所代表选民的赞成票数达到半数以上时才能投赞成票。在这个例子中,议员A、B、C都只代表三个选民,因而促使他们投赞成票的票数为2。给这个数字取个新名字:阈值。
于是伪民主制度便演化成了下面的数学问题:每个议员在投票时,不需再看自己到底代表了谁。他/她只需将所有选民的投票结果乘以其权重后相加,然后将总和与阈值比较,假如达到或大于阈值,就投赞成票,反之投反对票。
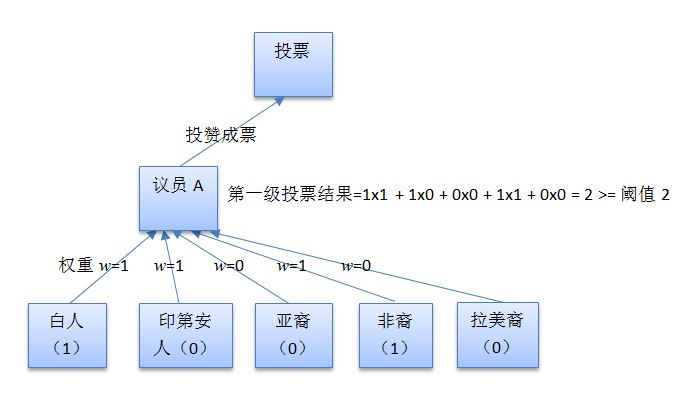
上图便是议员A在对平权法案表决时投票的全过程示意图。
假如能耐着性子读到这里,您就已经理解到神经网络的精髓了。其实神经网络并非深奥无比,其基本思路就是上面这个伪民主代议制的投票过程。
只不过,真正的神经网络,在其最底层绝不会只有五个投票的选民,一般也不会只有一级代议的议员。现在流行的神经网络一般有七级以上。为了与一般只有两、三级的神经网络相区别,这类网络往往被赋予“深度学习神经网络”等神圣的名称。
我们很快会看到,这样一个多级投票机制是怎样被用来解决生活中的实际问题的。
大家一定对手写汉字输入不陌生。在电话上刷刷写上几笔,对应的印刷体就会被调出来。电脑认识汉字,甚至还认识俺写的那些歪歪斜斜的汉字!
其实只要您懂得上面的伪代议制投票原理,理解汉字识别就不是什么难题了。
假设我们要教电脑识别阿拉伯数字“5” 。要想做这件事,首先我们要准备几个手写体的5和几个其他数字。
第一步,把这些手写体图像量化,变为16x16的点阵。笔划经过地方的值为1(赞成票),反之为0(反对票)。
第二步,建立多级代议制度,每一级都由一定数量的议员组成,这些议员都会收集前一级选民/议员的投票结果,把结果乘以权重后加起来,和阈值比较,然后根据比较结果决定自己投赞成票还是反对票。越往上议员越少,最高一级议员的投票直接决定议案通过与否。
第三步,把准备好的手写体样本送入投票系统,像议员操纵投票结果那样要求系统在看到手写体“5”时通过法案,而看到其他数字时否决法案。
人的脑子转得过来吗?当最底层选民的人数为五时,做做手脚是很容易的;然而,当这个数字变为16x16=256,需要表决的法案成百上千时(其实就是各种手写体数字的变种),人们应该怎样选择各级的权重以及阈值使这个网络输出我们希望得到的结果呢?
我们可以一个一个地试呀!先为每个选民/议员随机地选择一个权重和阈值,然后看看能否达到我们希望的结果。如果不行,就调整一些权重和阈值再试,如果还不行,就再换……
熟悉吗?蛮力搜索!用人脑去操纵民意只能在很小的规模上进行。可一但用上电脑的蛮力,能够操纵的规模就大多了。尤其是在电脑的计算能力日新月异的今天,计算成千上万个输入、七层以上的神经网络已经不是难题了。当然,真正神经网络的计算并非完全靠蛮力,但就像前面计算围棋问题一样:那其实是一种优化后的蛮力,电脑的蛮力精神依旧在这里被发扬光大。
需要说明的是,真正神经网络的权重和阈值可以任意设置:它们不必局限于0、1或者正整数,可以是小数、负数。在做权重相加时一般也不会只做简单的线性相加,而是要引入更为复杂的算法。不过基本概念仍然不变。
那么神经网络为什么一定得搭那么多层,使计算变得复杂无比呢?少搭几层省下计算时需要的电量,不但省事,而且还绿色环保,不是更好吗?
不行,因为那样是解决不了问题的。
我们前面将神经网络比喻为伪民主代议制。想想政治家在想要隐蔽地达到自己的目的时会怎么做吧。当然是先把水搅浑,把问题搞得复杂无比,然后说,你们都玩不转了吧,现在我来定一套非常公平的投票方案吧,大家一人一票,然后一级一级地代议,最后得出一个结论,公平而又合理。
于是大家按照政治家们定出的规则投票,得到的结果正是政治家们预先设定好的。
政治家们发明这么多层的代议,就在于他们可以根据这个系统随便操控民意,他们想通过这个法案就通过,想否决那个法案就否决,想全部通过或否决所有的法案也是做得到的。要达到这些目的,他们唯一需要做的事,便是调整系统中的权重和阈值。选民们被瞒天过海,还以为自己的投票得到了公正合理的计数。
科学家们发明了神经网络,就在于这个网络可以任意操纵评估结果。你把一张人脸照片送入系统,是可以通过操控权重和阈值使系统输出“这是人脸”的结果的。你再把另一张人脸照片送入系统,同样可以通过操控权重和阈值让系统在看到这两张照片的任何一张时都输出“这是人脸”的结果。现在重复上述步骤,把各类人脸、猫脸、狗脸、狐狸脸的照片都往系统里送,并让系统在看到人脸照片时最终投赞成票,看到其他照片时投反对票。
当我们使用了足够多的照片,对整个系统的参数进行了无数次微小的调整之后,奇迹便会出现:此时,即使拿来一张系统从未见过的人脸照片,它也会输出“这是人脸”的答案。
神经网络会“学习”了,能够识别没有见过的物体了!
然而如果我们仔细想想上述过程,就会明白其中的机理:这张新照片一定是和曾被用来训练系统的某一张或几张照片有着某种相似性,因而在投票时产生了类似的投票分布,所以才会最后输出我们希望看到的结果。
神经网络的最基本的要求,就是必须用海量的样本来训练它。
因为,唯有如此,才能提高新照片与某(几)张样本照片有较高相似度的可能性(样本照片都会输出人所希望的结果),从而产生类似的投票结果,完成“学习”的过程。
然而,再完美的训练样本都会有意外。即使学习了数十亿张的人脸照片后,一定会有一些新照片并不与任何样本照片产生足够的相似度。这就是迄今为止,所有人脸识别系统都无法做到百分之百识别率的原因。
让我们从反面来理解这个问题。前面说过,现代神经网络一般都有七级以上的“代议”。把系统弄得这么复杂,就在于科学家们可以随意操控评估结果:他们可以让各种类型的人脸——哭的、笑的、愁的、郁闷的、皱纹斑斑的——在评估时都投赞成票。
但是,科学家们绝对有能力——虽然他们从来不这么做———把神经网络训练成将人脸与垃圾桶不分彼此,将青蛙与汽车轮胎相提并论,将天上的星星和少女脸上的青春痘混为一谈的系统。只要人愿意,神经网络是可以通过“学习”实现上述功能的。
因为,神经网络的实质就是:它的代议是万能的,任何两(多)种输入,不管它们是不是互为关联,都可以通过操控各层的参数产生同一评估结果。神经网络既弄不懂,也不会关心这些输入之间有没有逻辑上的联系。神经网络如何学习,就看人怎样训练它。
通过以上描述,我们可以归纳出神经网络的三个特征:1)必须有足够多的层数让操纵评估结果成为可能。2)必须用足够多的样本来训练网络,让网络产生人所希望的评估。3)实际使用时,输入网络的数据不能和这些样本相去太远。
仍以人脸识别为例。假如我们用各种脸型的照片来训练网络:圆的、方的、瓜子的、倒三角的……这时如果我们拿来一张半圆半方脸的照片,网络虽然没见过,却很有可能会识别出这是人脸,因为此时,那些对圆脸敏感的权重和对方脸敏感的权重会同时作用,在以后的代议中,这些权重会被叠加而最终输出“是人脸”这一结论。
然而,假如此时给网络看一张大胡子照片,它就不知所措了,因为样本里没有一张长胡子的照片。此时解决问题的唯一办法就是继续找来各种有胡子的人脸照片——长的、短的、山羊的、络腮的——来训练网络,以希望将来再次遇到长胡子的人脸照片时,会和这些新样本类似。
迄今为止多数人工智能产品都是基于上述原理而搭建的。虽然有各类让人眼花缭乱的变种,但万变不离其宗,因而也就保留了这些先天不足。想想我们熟悉的产品:物体识别、语音识别、机器翻译……都无一例外地打着这个烙印。近些年来发生在人工领域里的飞速进展,与其说是机器变得更聪明了,更会学习了,倒不如说是由于计算能力的增强和信息量的倍增,而使得操控评估结果变得更为可能和更有现实意义了。
神经网络其实更像一个没有思想的木偶:虽然它能在台上做出各种活灵活现、栩栩如生的表演,然而它自身并不知道自己所做的动作包含着怎样的意义,牵挂在它身上的一条条操纵线才是真正藏而不露的玄机。
话题终于可以绕回到围棋之上来了。用神经网络下棋,可能吗?
我们可以搭建一个类似人脸识别那样的多级评估结构。围棋盘的输入为19x19的点阵,每个点有3个状态(白子、黑子、无子),总信息量比普通低清晰度照片还少好几个量级!然后,我们可以把名家对局的棋谱输入网络,然后通过调整权重和阈值,使系统在看到已知棋局时都走出正确的落子。问题的关键就在于,这样训练出来的网络能否在看到未知棋局时也作出正确的判断。
直觉告诉我们这样做是行不通的,因为两个几乎一模一样的棋局,很可能就因为某个地方多了或少了一个子,接下来的下法就完全不同。比如说有一片黑棋,它中间没有眼,有一个眼或两个眼,对于下一步落子的意义是完全不一样的。
那么,有没有办法把不同的算法结合起来,取长补短,来打造一个强大无比的电脑围棋斗士呢?
待续
阶梯讲师原创作品•谢谢阅读
