徐令予博客
考槃在涧,硕人之宽。独寐寤言,永矢弗谖。考槃在阿,硕人之薖。独寐寤歌,永矢弗过。考槃在陸,硕人之轴。独寐寤宿,永矢弗告。



亚伦森教授反戈一击 挑落“九章”量子霸权
作者:徐令予
2020年底,中科大的“九章”团队宣称他们研制的光量子计算机取得了“量子优势”,很快国际上就有一些专家学者对此提出了批评和质疑[1]。但是批评者们大多只是谦谦君子,动口不动手,唯有谷歌量子计算理论部首席科学家 Sergio Boixo 与众不同,他是既动口来也动手,他带领他的研究团队设计制定了近似模拟算法和计算程序,在高斯玻色釆样的质量和效率上全面击败“九章”实验设备。具体的算法和数据开布在今年9月的研究报告中[2]。
谷歌的研究成果无异于一颗重磅炸弹,让玻色釆样的教主斯科特·亚伦森教授再也按耐不住了,他仔细阅读了谷歌的论文,并与谷歌的Sergio Boixo 和中科大的陆朝阳教授进行了认真的交流沟通,10月10日他发表一篇博文[3],反戈一击挑落了“九章”的量子霸权。
亚伦森教授文章的核心可以归结为两点:
- 在摸拟高斯玻色采样时,谷歌的经典近似算法得到的数据比“九章”实验设备更可信更有效,“九章”的量子优势没有科学依据;
- 玻色采样在实验上必须提髙数据的保真度,同时在理论上必须找到对实验结果可以验证的有效方法,没有这两个方面的突破,玻色釆样要取得量子优势就是盲人骑瞎马。
亚伦森教授是玻色釆样理论的开山始祖、“九章”论文在《科学》上发表时的主审人。在玻色釆样问题上没有谁比亚伦森教授更权威了,也没有任何人比他更希望玻色釆样早日取得量子优势,因此他对“九章”实验结果的否定就是终审裁决。
亚伦森教授是玻色釆样之父,玻色釆样之果就是取得量子优势,没有一位父亲不想早得贵子。亚伦森教授偏爱“九章”实验是人之常情,但是作为一个科学家他更爱真理,他认理不认亲,绝不护犊子。亚伦森教授科学之上的精神值得点赞!
为便于读者更好地阅读和理解亚伦森教授的原文,这里先对玻色釆样、量子优势和和“九章”实验作些科普介绍,有基础的读者可以直接跳转至摘译部分。
玻色釆样实验每次让100个光子通过一个100x100的全连接光干涉网络,然后在100个出口,分别用单光子检测器来检测有没有光子输出,见下图左侧。每次实验在200秒的时间之内,发射5000万批次的光子,每个批次有100个光子。然后观察100个通道出口的单光子检测器中一共检测到多少次光子,得到实验结果,见下图中间。把实验得到的样本数除上釆样总数就是各种光子数出现的概率分布,见图右侧的红色曲线(条件是釆样总数必须足够多,这一点至关重要[4])。
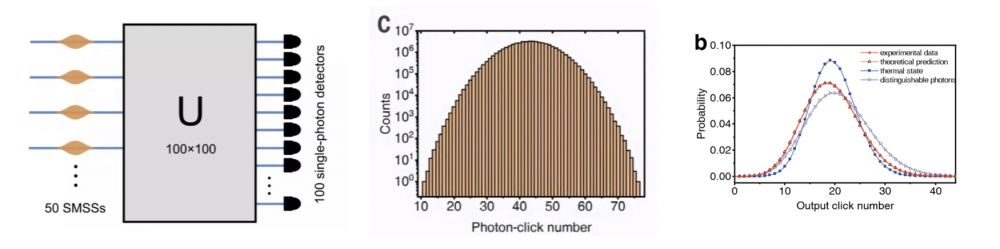
玻色釆样实验得到的了一个分布曲线,曲线上的每一点对应于100个通道口检测到某个光子数的概率,这个概率值可以把光子数作为自变量通过复数矩阵的积和式计算得到,积和式的精确算法是指数复杂度,因此当光子数足够大时,目前的经典数值计算机是无能为力的,而且玻色釆样一次实验同时得到各种光子数的概率,毕竟玻色采样就是一部釆样机,这是玻色釆样实验的优势所在。
但是有一点需要指出,玻色采样得到的概率仅是一个釆样的近似值,而超级计算机得到的却是精确解,当计算程序编制调试通过后,它们在不同的超算上,在不同的时间地点上,在外界环境变化时,得到的计算结果都是一样的,而玻色釆样实验就完全做不到这一点,同样的实验设备白天与晚上的结果都会不一样,更不要说换一台设备了。所谓的量子优势绝不表示玻色釆样实验设备运行积和式程序比超算更快,更准确地说,是用超算通过积和式数值解的方法模拟玻色釆样效率太低。那么是否存在对玻色釆样实验更为有效的数值模拟技术呢?答案是肯定的,这就是本文的核心。
对于有噪声的“玻色釆样”(BosonSampling)实验确实存在更有效的经典模拟,量子计算理论专家 Gil Kalai 和 Guy Kindler 在2014年发表的一篇论文指出,给定一个光子分束器网络,该网络的“玻色釆样”的分布也可通过逐级的分层模型作数值模拟逼近。
初浅地讲,在第一级(k = 1),假设光子只是经典的可区分粒子。在第二级(k = 2),模型精确模拟两个光子相互之间的量子干涉,但是没有高阶干涉。在第三个级别(k = 3),模型精确地模拟了三个光子相互之间的干扰,依此类推,直到 (k = n)(其中 n 是实验中每次光子输入的总数),这就能逐步逼近玻色采样的理想分布。
谷歌的研究团队在上述分层模型基础上,针对中科大的“九章”2型设备设计制定了具体的近似模拟算法和计算程序,在釆样的质量和效率上全面超越“九章”。有关详情可见他们近期发表的论文:《高斯玻色釆样实验的高效近似算法》。该论文简直就是一篇针对中科大“九章”团队的檄文,文章明确指出,复杂度仅为二次方的经典近似算法比“九章”实验可以更精确地逼近理想的分布,因此“九章”的量子优势就失去了科学依据。
下图是该论文中的图3。图中的黑色点线和紫色虚划线分别对应于理想分布曲线和“九章”釆样的实验结果,颜色为兰、绿、橙、棕的直线分别为一级、二级和三级近似的经典模拟计算结果。从图的上部可以看出,二级以上的近似计算结果更接近理论的分布曲线,图片的下部显示各种方法得到的结果与理论分布的统计偏差曲线,从中不难看出“九章”采样实验结果与理论分布之间的偏差远大于二级近似的计算结果。
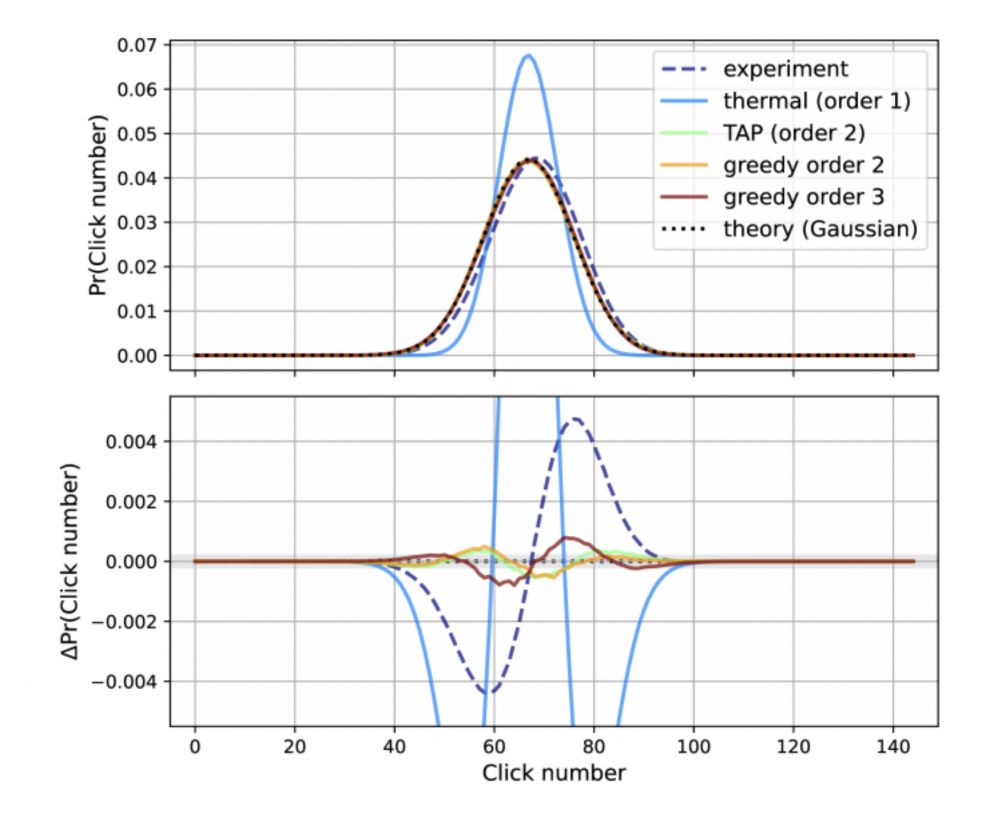
实验釆样和近似计算的结果谁更接近于理想分布呢?在上段文字中我们两次使用了“看出”一词,这显然不够科学,谷歌的论文中使用了一个客观指标:“总变差”
“总变差” (Total Variation Distance )通常是用来衡量两个概率分布之间的相似性和差异的,在应用中它虽不及 KL 距离那么广泛,但是在理论分析中用的比较多。两个分布的“总变差”越小则表示这两个分布很接近,或者说很一致。

从数据来看,与理论分布相比,谷歌的近似模拟算法的“总变差”小于“九章”实验结果的“总变差”,换言之,谷歌的近似模拟算法得到的釆样结果比“九章”实验的结果更接近于理论分布。而谷歌的近似模拟算法仅是二次方计算复杂度,因此在高斯玻色釆样上它比“九章”可以做得更快更好,“九章”的量子优势就是子虚乌有。
对此,亚伦森教授一针见血地指出,玻色釆样就是做采样的,它的名字就说明了一切!釆样得到的分布能否逼近理想分布是检验釆样结果的唯一标准,如果谷歌的近似算法在逼近理想分布上做得比九章实验更好,那么一切争论都是多余的。
“总变差”这个评价指标就是悬在中科大“九章”团队头顶的达摩克利斯之剑。在严峻的技术挑战面前,中科大团队缺乏“扎硬寨,打死仗”的决心和本事,只想迂回躲闪走偏路,他们拒绝把“总变差”作为主要的评价指标也属意料之中,这与他们从事量子通信工程化以来的行事风格相当一致。
为了把水搅浑,中科大团队避而不谈“总变差”,却在“高阶相关性”上大做文章,他们批评谷歌的近似算法只做了2阶和3阶相关性的近似模拟,宣称他们的实验涉及到19阶相关性。
但是他们却不敢承认这样两个事实:第一个事实是 k 阶相关性对分布的贡献按 1/exp(k) 指数式下降。第二个事实是,釆样实验结果在 1 阶和 2 阶相关性上已经与理想分布存在明显偏差。
“九章”实验设备就像一只蹩脚照像机,拍出的照片严重失真,却一味的夸耀自己像素有多高,实在令人啼笑皆非。
对于“高阶相关性”问题亚伦森教授的批评更为尖锐:难道中科大的九章实验真的在“高阶相关性”这个指标上做得更好吗?如果中科大的“九章”团队非要修改比赛规则,但在新规则下仍然输了比赛,那将是极为尴尬的。看来亚伦森教授真的生气了,不知中科大团队的某些人这次是否真能接受批评、迷途知返。
总之,谷歌最新的论文否定了“九章”取得量子优势,并且得到了玻色釆样理论创始人兼“九章”论文审稿人亚伦森教授的背书。亚伦森教授文章的最后为玻色采样的未来作出了新的规划,他认为玻色采样要真正取得量子优势必须在以下二个方面同时取得突破:
1)在实验方面,重点是提高采样数据的保真度(Fidelity),而不是一再扩大实验系统的规模(Hilbert space);
2)在理论方面,需要找到能够有效地验证实验结果正确性的标准和方法。
亚伦森教授不愧是玻色采样的祖师爷,他对玻色采样目前存在的问题看得一清二楚,点到了“九章”实验的死穴上了。目前“九章”高斯玻色采样实验数据的保真度比经典近似模拟算法差很多,而且在高光子数的区间的实验结果也根本无法验证,在这种情况下,宣称“九章”已经取得量子优势实在为时过早。
更令人不可思议的是,中科大某些人明知“九章”的釆样结果与理论分布差距甚大,特别是在决定性能的高光子数区间的实验结果无法验证的情况下,仍然在媒体上公开宣传“九章”比超算要快“亿亿亿”倍,这已经很难用“错误”做遁词了,这种不负责任误导公众的行为已经严重突破了做人的底线。
“ Quantum Supremacy ”原意就是“量子霸权”,为了政治正确现在都用“量子优势”替代了。其实“九章”从未真正取得过量子优势,却非要说已经取得量子优势,还不容他人批评质疑,“九章“是量子优势全无而量子霸权十足。清除“九章”问题上某些人的霸权思维才是这此争议的要害所在,所以本文的题目取为:《亚伦森教授反戈一击 挑落“九章”量子霸权》
亚伦森教授2021年10月10日博文摘译
(…… )。如果经典模拟算法在与理想分布的“总变差”这个指标上击败玻色采样实验,那就没有必要再为正确再现高阶相关性这个指标操心。
确实,目前有噪声的玻色采样实验是建立在两个事实的基础上的。第一个事实是 k 阶相关性对分布的贡献按 1/exp(k) 指数式下降。第二个事实是,由于校准错误等原因,釆样实验结果在 1 阶和 2 阶相关性上已经与理想分布存在明显偏差。
把这些事实放在一起,你会发现什么?经典模拟算法仅考虑低阶相关性贡献后得到的分布完全正确。单凭这一点,它已经胜过了有噪声玻色釆样实验,作出这个判断的指标就是与理想分布的“总变差”或“线性交叉熵”。是的,玻色釆样实验在高阶相关性这个指标上将胜过经典模拟。但由于这些高阶相关性无论如何都会呈指数衰减,因此它们不足以勉回总体的评估。玻色釆样实验在低阶相关性上的不完美是致命伤。
(Now for the kicker: it seems that Hypothesis H is false. ) A classical spoofer could beat a BosonSampling experiment on total variation distance from the ideal distribution, without even bothering to reproduce the high-order correlations correctly.
This is true because of a combination of two facts about the existing noisy BosonSampling experiments. The first fact is that the contribution from the order-k correlations falls off like 1/exp(k). The second fact is that, due to calibration errors and the like, the experiments already show significant deviations from the ideal distribution on the order-1 and order-2 correlations.
Put these facts together and what do you find? Well, suppose your classical spoofing algorithm takes care to get the low-order contributions to the distribution exactly right. Just for that reason alone, it could already win over a noisy BosonSampling experiment, as judged by benchmarks like total variation distance from the ideal distribution, or for that matter linear cross-entropy. Yes, the experiment will beat the classical simulation on the higher-order correlations. But because those higher-order correlations are exponentially attenuated anyway, they won’t be enough to make up the difference. The experiment’s lack of perfection on the low-order correlations will swamp everything else.
当然,我仍然不确定会发生什么— 是否能将“总变差”的判断标准外推到全部 144 模式中,这取决于我是相信(谷歌的)Sergio Boixo 还是(中科大的)陆朝阳,(在这一点上我有些难以取舍)。但我现在看到(谷歌的判断)在逻辑上是可能的,甚至可能是合理可信的。
Granted, I still don’t know for sure that this is what happens — that depends on whether I believe Sergio or Chaoyang about the extrapolation of the variation distance to the full 144 modes (my own eyeballs having failed to render a verdict!). But I now see that it’s logically possible, maybe even plausible.
谷歌可以说:玻色釆样的创始人斯科特·亚伦森(Scott Aaronson)在上周晚些时候认为用一个指标—即与理想分布的“总变差”,就完全足够做出评判,那么我们就赢了。我们实现了比中科大九章实验更低的“总变差”,我们使用了快速的经典算法。争议结束。落棋不悔,方为君子。
谷歌还可进一步强调:玻色釆样是一个采样任务,它的名字说明了一切!釆用任何判断标准的唯一目的—无论是线性 XEB 还是高阶相关性,都是为了判定你的釆样结果能否逼近理想分布。这就意味着,如果承认我们在逼近理想分布上做得比九章实验更好,那么就再也没有什么可争论的了。
Google could say: by a metric that Scott Aaronson, the coinventor of BosonSampling, thought was perfectly adequate as late as last week — namely, total variation distance from the ideal distribution — we won. We achieved lower variation distance than USTC’s experiment, and we did it using a fast classical algorithm. End of discussion. No moving the goalposts after the fact.
Google could even add: BosonSampling is a sampling task; it’s right there in the name! The only purpose of any benchmark — whether Linear XEB or high-order correlation — is to give evidence about whether you are or aren’t sampling from a distribution close to the ideal one. But that means that, if you accept that we are doing the latter better than the experiment, then there’s nothing more to argue about.
中科大九章团队可能会做出回应:即使斯科特·亚伦森(Scott Aaronson)是玻色釆样的创始人,他也远非是绝对可靠的预言家。在这个现实案例中,他对实验中的错误来源缺乏认识,导致他不恰当地将“总变差”作为判断成败的唯一指标。如果你想看到我们系统中的量子优势,你必须忽略低阶相关性而更多地关注高阶相关性。
中科大团队也可补充:从一开始,量子优势实验的重点就是在某个标准上展示明显的加速—我们从不特别关心是哪一个指标!一开始当我们谈论到量子优势时,习惯己成自然 — 谷歌团队自己在 2019 年秋季报告第一次量子优势实验时,同样用的是一个完全人为的标准,这是众人皆知的事实。(Google 团队甚至有调整标准的先例,例如,当 Pan 和 Zhang 指出最初指定的 Linear XEB 很容易被随机 2D 电路模似时,他们的反驳就是:好,那就这样吧,添加一个额外检查使得返回的样本彼此足够的不同,这就秒杀了 Pan 和 Zhang 的模拟策略。)那么凭什么针对高阶相关性量身定制的指标就一定不如“总变差”或“线性交叉熵”或任何其它指标呢?
USTC could respond: even if Scott Aaronson is the coinventor of BosonSampling, he’s extremely far from an infallible oracle. In the case at hand, his lack of appreciation for the sources of error in realistic experiments caused him to fixate inappropriately on variation distance as the success criterion. If you want to see the quantum advantage in our system, you have to deliberately subtract off the low-order correlations and look at the high-order correlations.
USTC could add: from the very beginning, the whole point of quantum supremacy experiments was to demonstrate a clear speedup on some benchmark — we never particularly cared which one! That horse is out of the barn as soon as we’re talking about quantum supremacy at all — something the Google group, which itself reported the first quantum supremacy experiment in Fall 2019, again for a completely artificial benchmark — knows as well as anyone else. (The Google team even has experience with adjusting benchmarks: when, for example, Pan and Zhang pointed out that Linear XEB as originally specified is pretty easy to spoof for random 2D circuits, the most cogent rejoinder was: OK, fine then, add an extra check that the returned samples are sufficiently different from one another, which kills Pan and Zhang’s spoofing strategy.) In that case, then, why isn’t a benchmark tailored to the high-order correlations as good as variation distance or linear cross-entropy or any other benchmark?
为了进一步论证的需要,假设我们接受了中科大的立场,并且我们认同中科大的九章实验取得了量子优势,如果“九章”实验在再现高阶相关性方面确实比任何已知的经典模拟做得更好。但我们仍然面临一个问题:难道中科大的九章实验真的在该指标上做得更好吗?如果中国科学技术大学赢得了可以单方面修改游戏规则的权利,但即使在新规则下仍然输了比赛,那将是极为尴尬的。
OK, but suppose, again for the sake of argument, that we accepted the second position, and we said that USTC gets to declare quantum supremacy as long as its experiment does better than any known classical simulation at reproducing the high-order correlations. We’d still face the question: does the USTC experiment, in fact, do better on that metric? It would be awkward if, having won the right to change the rules in its favor, USTC still lost even under the new rules.
那么,为什么我们没有 19 阶相关性的直接数据呢?问题很简单,它会让中科大花费天文数字的计算时间。因此,他们只能依赖于观察到的低阶相关性数据的统计外推—我们再次进行外推!当然,如果我们不让谷歌作合理的外推,但是又放任中科大可以作相同的事情,那与游戏又何区别?
So then, why don’t we have direct data for the order-19 correlations? The trouble is simply that it would’ve taken USTC an astronomical amount of computation time. So instead, they relied on a statistical extrapolation from the observed strength of the lower-order correlations — there we go again with the extrapolations! Of course, if we’re going to let Google rest its case on an extrapolation, then maybe it’s only sporting to let USTC do the same.
对于量子优势实验的未来,有三个目标比以前更为紧迫。
1)对于采样实验,提高设备的数据保真度(例如,对于玻色釆样,观察高阶相关性对分布的贡献)— 从战胜经典模拟算法的角度来看,这比进一步增加希尔伯特空间维度更为紧迫。
2)从理论上讲,要制定更好的标准,使得可以用经典算法对基于采样取得量子优势的实验结果进行验证 — 理想情况下,该经典算法应该是多项式复术度。
3)特别是高斯玻色釆样,应更好地了解经典模拟算法的合理边界,以及有噪声的量子设备需要达到怎样的数据保真度才能超越这些边界。
In the end, then, I come back to the exact same three goals I would’ve recommended a week ago for the future of quantum supremacy experiments, but with all of them now even more acutely important than before:
- Experimentally, to increase the fidelity of the devices (with BosonSampling, for example, to observe a larger contribution from the high-order correlations) — a much more urgent goal, from the standpoint of evading classical spoofing algorithms, than further increasing the dimensionality of the Hilbert space.
- Theoretically, to design better ways to verify the results of sampling-based quantum supremacy experiments classically — ideally, even ways that could be applied via polynomial-time tests.
- Gaussian BosonSampling in particular, to get a better understanding of the plausible limits of classical spoofing algorithms, and exactly how good a noisy device needs to be before it exceeds those limits.
参考资料
[2] 高斯玻色釆样实验的高效近似算法
[3] 亚伦森教授10月10日的博文
[4] 基于量子随机的玻色采样行为级模拟

我同意你的观点,世界各国的量子计算研究基本上都是忽悠,不过中国的忽悠骗的都是政府的钱,性质更恶劣。
谢谢关注留言。
谢谢关注留言。
谢谢关注留言。
打不打脸不重要,
没人愿意打那些说假话的人的脸,怕脏了g手。
前有亩产万斤,今有量子研究第一,
革命自有后来人,呵呵
中国人被打脸,博主兴奋不已,浮表字面,爽呀!
---------------------
文学城这样的人不少,可能美国的汉堡吃多了。